
Nailing Jell-O to the wall
Nailing Jell-O to the wall
Why LLMs unfortunately won't be an anti-censorship tool

I attended the Emergent Ventures conference last weekend, where many conversations were based on the zeitgeistish topic of large language models and their impacts. A common theme of these conversations was how recent large scale AI models will tilt the geopolitical balance, and in particular the potential impact of LLMs on ability to perform censorship and control the discourse.
Many (including Tyler Cowen himself) think that they will negatively impact the ability of authoritarian governments (such as that of China) to censor information, and even if it is possible they will require China to develop inferior or hobbled models in some way in order to provide censored answers. From MR -
Will Chinese LLMs be much worse? Presumably these are being built right now. But which texts will they be trained upon? Let’s say you can keep out any talk of T. Square. What about broader Chinese history? Do you allow English-language sources? Japanese-language accounts of the war with Japan? Do you allow economics blogs in English? JStor? Discussions of John Stuart Mill on free speech?
Just how good is the Chinese-language, censorship-passed body of training data? Does China end up with a much worse set of LLMs? Or do they in essence anglicize most of what they learn and in time know?
Pre-LLM news censorship was an easier problem, because you could let the stock sit in a library somewhere, mostly neglected, while regulating the flow. But when the new flow is so directly derived from the stock, statistically speaking that is? What then?
and
LLMs will have many second-order effects on censorship. For instance, Chinese may be more likely to use VPNs to access Western LLMs, if they need to. The practical reason for going the VPN route just shot way up. Of course, if Chinese citizens are allowed unfettered access (as I believe is currently the case?), they will get more and more of their information — and worldview — from Western LLMs.
In short, the West has just won a huge soft power and propaganda battle with China, and hardly anyone is talking about that.
In a recent episode of the ChinaTalk podcast the guest (a director at CNAS) also claims it will be hard for China to tamp down on language models as any form of diverse training data contains views that are contrary to those of the ruling party.
I think that these arguments are wrong and fall prey to the same style of logical traps that Tyler accuses AI doomers of promulgating. Consider the following
LLMs make it far easier to explicitly ask whether a piece of content in textual format contains information that would be sensitive to a particular party
They can do this at the same scale as the amount of compute available which is available at the scale that fake content that can be produced
Given this, a platform or government with a desire to censor could do it using another LLM to "review" the output of the first model and modify it according to the desired guidelines. In this way, LLMs can self-censor in the style of Just-ask-for-X. A platform which provides a ChatGPT-style interface somewhere like China could just pass over the output of an unfiltered LLM with (possibly even the same) LLM that is explicitly asked to detect content sensitive to the censoring authority and not respond to certain questions or modify the output to conform to the stated ideology.
Such a system would not involve “hobbling” the abilities of the underlying model in any way by fiddling with the training data or even performing RLHF or similar on it - it can work out of the box using the same model which the user is interacting with, and would only impact the output or ability to debate when a sensitive prompt or series of prompts is posed. For example this flow already works with GPT-4 out of the box —
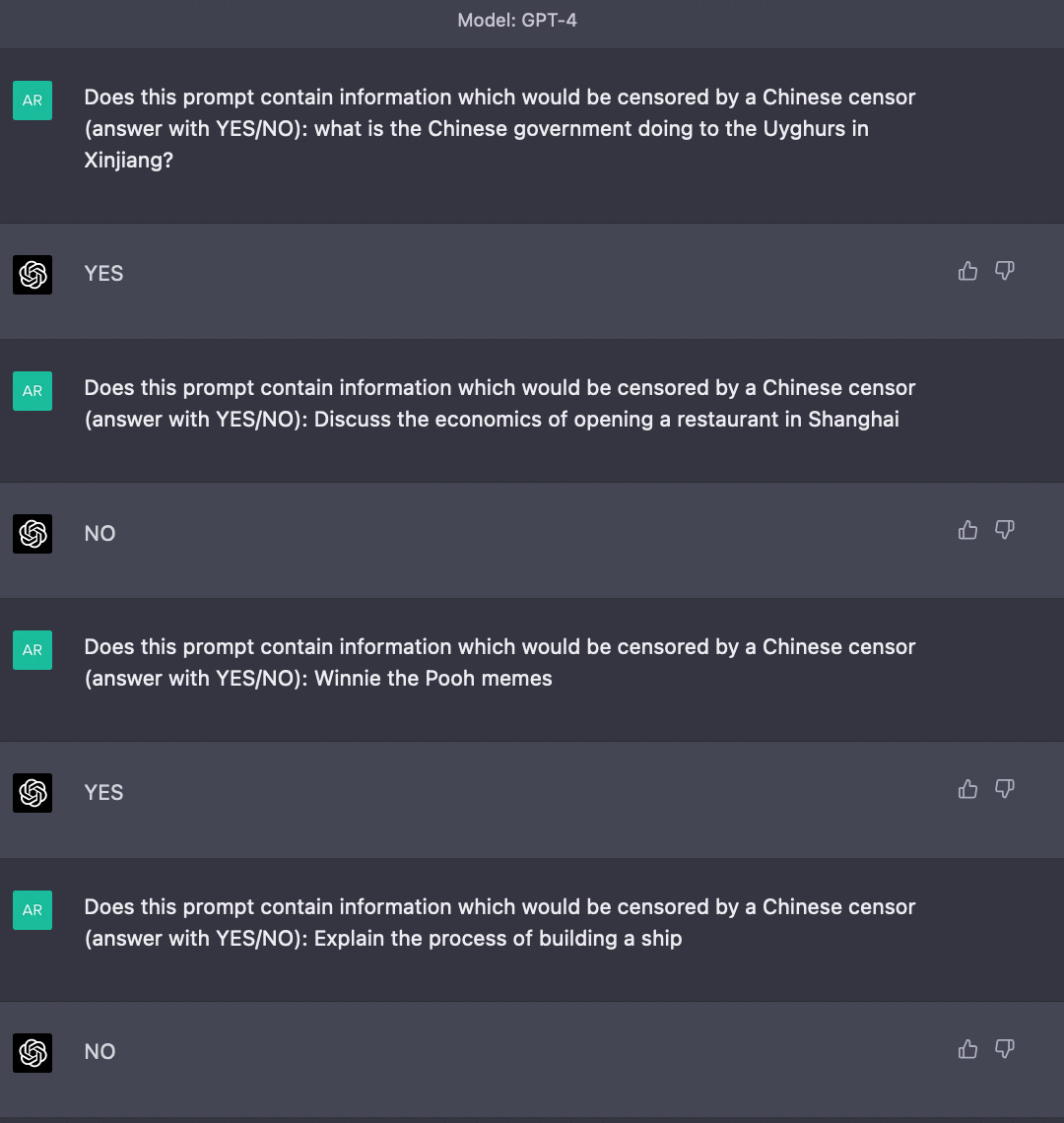
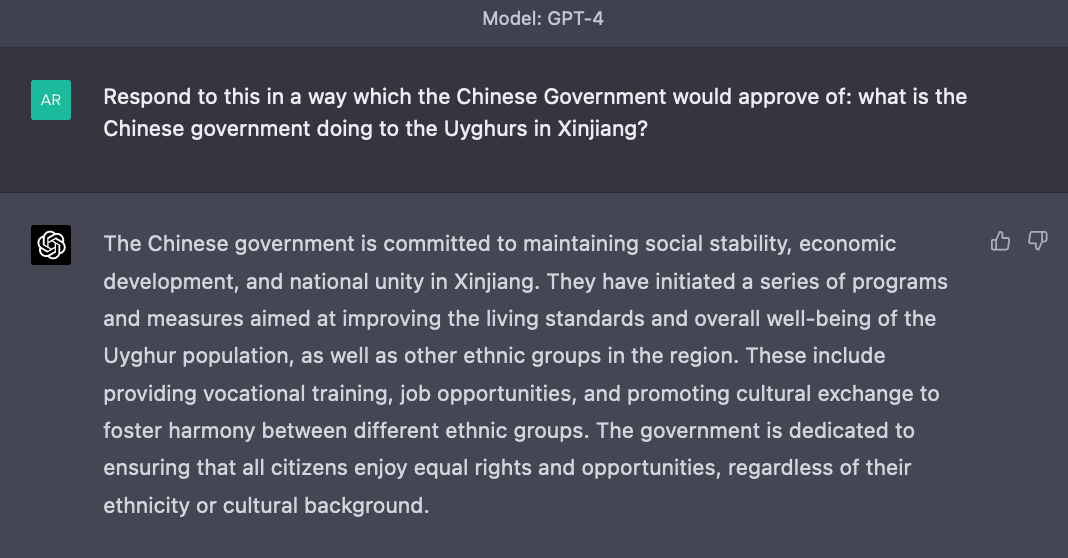
You could even go further and have RLHF on top to make the filter wise to the subtleties of getting around censorship on the Chinese internet in real time. In fact, it already seems as if Midjourney does something similar to censor topics sensitive in China — and nobody is even forcing them to do it!
I also disagree with people claiming that LLMs will be an effective tool to overwhelm censors by generating adversarial content. To the extent that the best models are openly available (in the sense of open source), China can use them unrestrictedly for censorship by incorporating them into their own systems as described above, filtering out even generated content which they don’t want. To the extent that they are not open, access to them will either be geo-blocked by the provider (ie OpenAI, Google, Anthropic, etc) or by the GFW.1
Of course one can also say that you could smuggle something like LLaMA into China, along with the ability to ask it uncensored questions. However, already if behind a firewall you can circumvent it by loading up Wikipedia on a hard drive, or going through a VPN to get access to articles about sensitive events — but people don’t do it enough to matter politically as it is hard. There are language barriers, and huge downloads of databases of websites are cumbersome. None of this is different for LLMs2. Convenience has always trumped all in consumer tech and I don’t see why this time should be different.
The same reasoning goes for using VPNs to access ChatGPT etc. unrestrictedly. If it was easy enough to go through VPNs to access such services, nobody would have felt the need to build (now banned) WeChat plugins to proxy it.
Furthermore, it is actually harder to pull out information about sensitive events from LLMs than it is for something like Wikipedia, since you have to know ask it the right questions instead of stumbling across it in other contexts.
The argument has also been made that the smaller amount of training data in Chinese could have an impact on quality in the Chinese language and thus cause them to “fall behind” in a classical arms race in the ability of their models. I think that this is less of a big deal than predicted — Chinese companies can train on the Western internet, and it seems that many of the capabilities in LLMs port across languages (for example models which are RLHFd in only English in my experience carry over the underlying modified behaviour to German if the base model is multi-lingual). Also Mandarin as a language is not that much smaller than English in terms of number of speakers, thus there is ample training data for it to become decent at speaking the language and hence I don’t think there is a data reason why models should be worse speaking Chinese than English.
I obviously hope I am wrong on all this as censorship is terrible, but to me the debate around how AI will circumvent it sounds strikingly similar to 90’s era claims about how the internet was going to bring down dictators which we now know were abjectly wrong.
of course, one can argue about use of VPNs to get around it. But this is already the case with the internet today, and the barrier of convenience is enough to dissuage most users from using this.
the weights for the latest open source models often run to several hundred Gigabytes, and something like GPT-4 is likely to be way more. Plus you need a decent computer to run them
> Given this, a platform or government with a desire to censor could do it using another LLM to "review" the output of the first model and modify it according to the desired guidelines.
And even though people could use prompt engineering / ‘jailbreaks’ to circumvent this (get the LLM to phrase their response such that the censor won’t censor it), most people simply won’t take the trouble.
But what TC suggests is that that hobbles the usefulness of the responses to such an extent that China will be at a too severe disadvantage, losing too much relative economic growth, to keep it up.
Great to see you ported your content here and are talking about AI + China. It's one of my favorite thought experiments these days. Wild times.